MiniChess-RL: Deep Q-Network Agent in a Custom 4×4 Chess Environment
MiniChess-RL is a fully custom reinforcement learning environment where a Deep Q-Network agent is trained end-to-end in a 4×4 chess setting. The project focuses on environment modeling, reward shaping, illegal action masking, and structured evaluation with reproducible experiments.
Research Question
How do reward design choices and environment modeling decisions affect learning stability and measurable performance in a compact chess-like MDP with a large discrete action space?
System Design
- Custom Gym-style environment with full MDP formalization
- State encoding: 4-channel tensor (WK, WR, BK, turn)
- Action space: 256 discrete actions (from × to)
- DQN with replay buffer and target network stabilization
- Epsilon-greedy exploration strategy
- Evaluation pipeline with reward-curve visualization
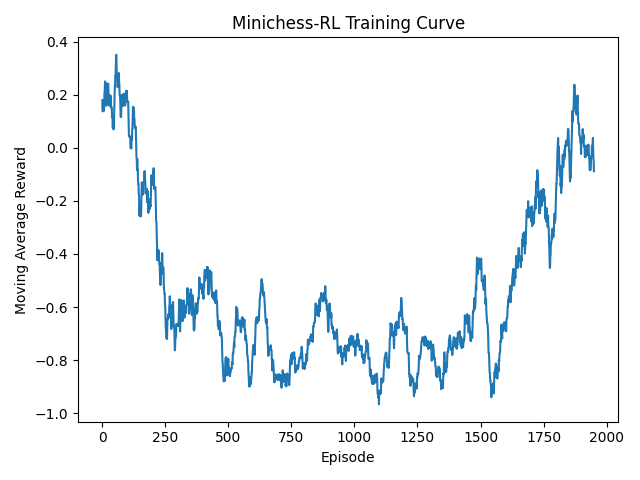
Experimental Results
Training Episodes
2000
Win Rate vs Random
19%
Average Reward (100 eval episodes)
-0.588
Results demonstrate partial learning behavior and highlight the sensitivity of reward shaping and exploration scheduling in compact adversarial environments.
Reproducibility
Train:
python3 training/train.py
Evaluate:
python3 training/evaluate.py
Experiments were conducted using PyTorch with a fixed evaluation protocol and greedy policy testing.
Future Directions
- Reward shaping ablation studies
- Multiple seed evaluation for variance analysis
- Self-play extension and stronger baselines
- Architectural comparison (Double DQN / Dueling DQN)